前面我们讲到了指向变量的指针和指向一维数组的指针,这篇文章我们来讨论一下指向二维数组的指针。
对于二维数组指针,需要注意的是对于不同情况下的下标变化,指针保存的地址值增加的长度(步长)是不同的,以下我们看一下不同情况下指针步长有什么规律(部分内容可能涉及简单的汇编来帮助理解)。
我们先看以下代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
#include <stdio.h> int main(int argc, char **argv) { int num[2][3] = { 1, 2, 3, 4, 5, 6 }; int (*p)[3] = num; printf("num = %p\n", num); printf("p[1] = %p\n", p[1]); printf("*p[1] = %d\n", *p[1]); printf("(*p)[1] = %d\n", (*p)[1]); printf("(*p)[5] = %d\n", (*p)[5]); return 0; } |
编译运行结果:

接下来我们一点一点的分析为什么是这些结果。
首先我们定义并初始化了一个二维数组,它在内存中可以表示为如下形式:
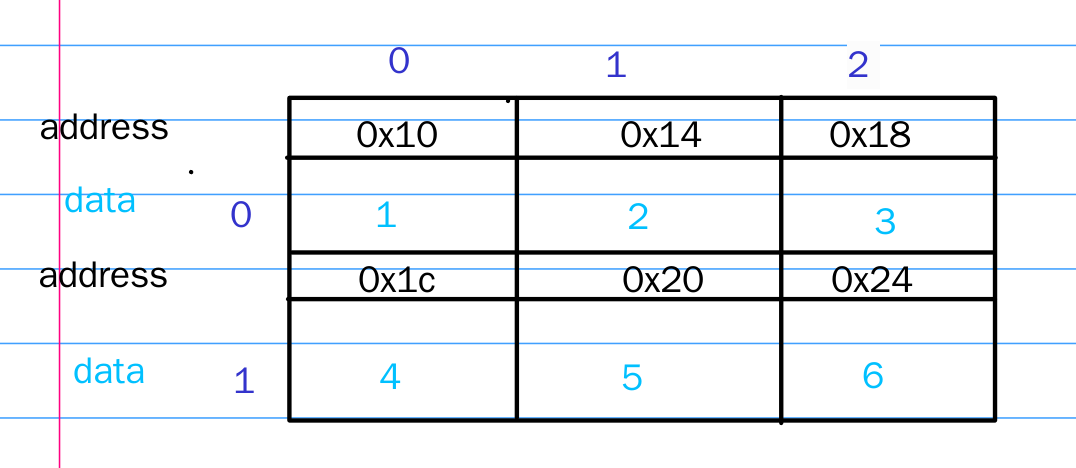
这里我们假设的是数组起始地址值为0x10(实际地址虽然也打印出来了,不过太长就不用了),其中蓝色的是数据,黑色的是数据所在的内存地址,紫色是数组的行号和列号,即下标。(其实它们在内存上是线性排列的,这样画是为了便于理解)
接着我们定义了一个指向该二维数组的指针p,并将num的值(0x10)赋值给了它,现在p=0x10。
|
1 2 3 |
int (*p)[3] = num; |
对于上述代码,可以看成这样 int[3] *p; 也就是我们定义了一个*p, 指向的是包含3个int型元素的数组。因为*操作是从右向左结合的,而小括号优先级最高,所以*p会结合成一对,这样理所当然的int和[3]结合在一起了。
扩展一下,如果我们定义成如下形式又表示什么意思呢?
|
1 2 3 |
int *p[3]; |
根据前面提到的结合方向,我们可以得出上述代码可以理解成int* p[3];也就是我们定义了一个数组,且该数组有3个元素,元素类型为int*,即数组里的每个元素都是指向int型的指针,这个我会在后面指针剩余部分提到,那就是另一篇文章了,也就是所谓的指针数组了。
点到为止,我们继续分析一下原来的代码。
假设p的地址为0x30,此时的数据分布可以用下图表示:
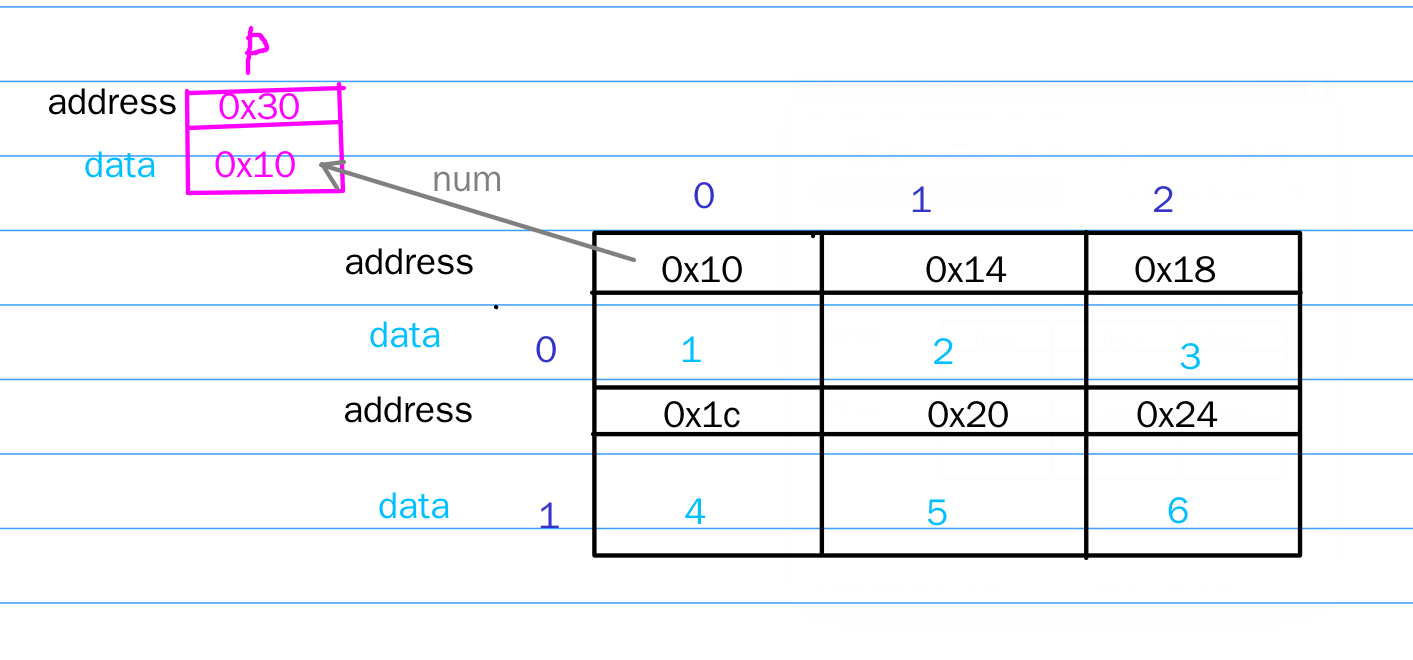
可以看到,num是一个地址,值为0x10,它即是作为第一行三个int型数据数组的首地址,也是整个二维数组的首地址。
|
1 2 3 |
printf("p[1] = %d\n", p[1]); |
以上代码中的p[1],会首先获得指针p里面存的内容0x10,然后在根据下标获得真正目标的地址值,具体这个下标1表示的步长究竟是多少呢?我们再看一下定义时候的代码:
|
1 2 3 |
int (*p)[3]; |
由上面的讨论我们知道,我们定义的是一个指针*p,该指针指向了一个包含3个int型变量的数组。即,我们每次对p加1,实际需要跨过的地址便是1*sizeof(int[3])=4*3=12字节了,所以p[1]会和数组的首地址相差12个字节。
对应会实际代码的运行结果,我们算一下到底是不是这样呢? num = 0x7ffc54dc4920 p[1] = 0x7ffc54dc492c
则可得出差值 = 0x7ffc54dc4920 – 0x7ffc54dc492c = 0xc,转化成10进制的话,就是12了,与我们推测计算的一样!
承接上面的结论,既然p[1]是num的地址基础上再跨越了3个int型数据,那么它的地址就是第4个int型数据的地址了,即使下图的第4个元素,值为4的地址,再取*操作,就得到了该地址下面的值为4了。
而这句为什么打印的不是4呢?
|
1 2 3 |
printf("(*p)[1] = %d\n", (*p)[1]); |
因为我们加了一个小括号,使指针p和*号先结合起来了,这就会先完成*p操作,获得num的首地址0x10,又因为数组num是int型数据的,所以会再根据下标1,完成了地址偏移量计算1*sizeof(int)=4,再计算出最终目标地址是0x10+0x04=0x14,这时就有点像数组索引了,因为*p就是数组的首地址,再加一个下标值,便会取出对应地址0x14的数据了,所以得到的结果便是(*p)[1])=2了。
再看一下最后一句:
|
1 2 3 |
printf("(*p)[5] = %d\n", (*p)[5]); |
按照上面一条讲的那样,*p取得了num的地址,再计算出地址偏移量=5*sizeof(int)=20(即0x14);那么目标地址即是:0x10+0x14=0x24,对应的值就是6了。
我们再推测一下,如果是num[5]是不是得到一样的结果呢?
毕竟刚刚*p可就是num的值啊。转化一下不就是(*p)[5] = num[5]吗?
其实,不是这样的,数组和指针还是有区别的,毕竟它们本身就是不同的数据类型,只是在某些情况下有一些互通的地方,加之数组名代表了数组的一个地址,不可以给它赋值,而指针是可以的,其次,当用sizeof(num)和sizeof(p) 时得到的分别是数组的大小(而不是num代表的地址值的数据大小)和指针的大小(8字节,占用64位)。
所以如果是num[5]的话,那么第一个下标指的是行,而每行是3个int型元素,下标每加1,代表跨过了一整行,那就是sizeof(int[3])=12字节了,num[5]相比于首地址偏移地址量就为12*5=60了。
而(*p)[5]是取得了首地址num,而num是int型数组,每个元素占用sizeof(int)=4字节,所以偏移地址量就是4*5=20了,相比于num[5]的60,实在相差甚远。
为了验证上面的的推论,我们再写一段代码,打印出num+60的值和&num[5]的值进行比较,如果相等就说明推论正确,如果不相等,我们就得再推敲推敲了。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
#include <stdio.h> int main(int argc, char **argv) { int num[2][3] = { 1, 2, 3, 4, 5, 6 }; int (*p)[3] = num; printf("num+60 = %p\n", num+60); printf("&num[5] = %p\n", &num[5]); return 0; } |
运行结果如下图:
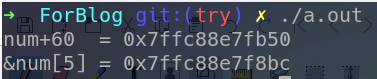
诶,不是说应该相等吗,怎么不相等?难道推论是错的?
不着急,听我细细道来,其实我也是第一次运行,按理说不应该出现这个错误,应该是哪里出了问题或者我们对代码的一些理解有误,编译器对这段代码的编译和我们认为应该要怎么计算不相符。
那我们来看一下这段代码对应的汇编指令究竟干了什么,我们使用objdump将刚刚的代码反编译一下:
|
1 2 3 |
objdump -d -S a.out > issue.s |
我们只看对应代码的部分,其它我们不必关心,所以这里我就只贴出对应部分啦:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
printf("num+60 = %p\n", num+60); 1199: 48 8d 45 e0 lea -0x20(%rbp),%rax 119d: 48 05 d0 02 00 00 add $0x2d0,%rax 11a3: 48 89 c6 mov %rax,%rsi 11a6: 48 8d 3d 57 0e 00 00 lea 0xe57(%rip),%rdi # 2004 <_IO_stdin_used+0x4> 11ad: b8 00 00 00 00 mov $0x0,%eax 11b2: e8 89 fe ff ff callq 1040 <printf@plt> printf("&num[5] = %p\n", &num[5]); 11b7: 48 8d 45 e0 lea -0x20(%rbp),%rax 11bb: 48 83 c0 3c add $0x3c,%rax 11bf: 48 89 c6 mov %rax,%rsi 11c2: 48 8d 3d 49 0e 00 00 lea 0xe49(%rip),%rdi # 2012 <_IO_stdin_used+0x12> 11c9: b8 00 00 00 00 mov $0x0,%eax 11ce: e8 6d fe ff ff callq 1040 <printf@plt> |
首先,数组的地址在这段指令运行之前,已经初始化到rbp-0x20处了。
代码最前面的1199之类的是代码存放地址,中间的 48 8d 45 e0之类的是汇编指令对应的机器码,lea -0x20
那么我们从第一条代码开始详细阐述一下:
|
1 2 3 |
lea -0x20(%rbp),%rax |
lea是加载有效地址的意思,-0x20
|
1 2 3 |
add $0x2d0,%rax //$0x2d0代表立即数 |
再看一下这句,意思是将rax的值加上0x2d0,再赋值回给rax,即rax = rax + 0x2d0.
将以上两句对比一下第9,10句,发现有什么不同吗?
没错,将数组的首地址(汇编上的基地址)加载到寄存器eax后,执行的add指令后面的立即数大小不同,有什么特点呢?
&num[5]在翻译成汇编指令时是num的首地址加上0x3c,即十进制的60,这个是无疑的。
而num+60在翻译的时候变成了num首地址加上0x2d0,转化成十进制就是720,有没有发现它跟12和60有什么关系?
Right!恰好是两个这数的乘积。
可为什么会这样呢?
由此其实不难推出了,在执行num+60的操作时,编译器并不是直接翻译成num的首地址+60,而是依然将num作为二维数组首地址,将60当成了它的下标,所以计算偏移地址的时候就变成了:目标地址=首地址+sizeof(int[3])*60 = 首地址 + 720了。
当将num+60中的num换成其他指针会怎样呢?
其实也是差不多的,首先编译器会获得这个指针指向的数据类型的大小,再根据加上的数值,计算出目标地址。我们假设指针指向的数据类型为A,加值为5,即p+5,那么,目标地址=p的地址值+sizeof(A)*5;
那是不是遇到这种问题就一定要用汇编解决呢?
当然不是啦,可以将num+60的值和num作差相减也能得到720,再顺着推理下去,只不过相对于直接看汇编来说还要多转一步,汇编的话会直观一点。
ok,接着原来我们需要验证的:&num[5]的值是num首地址加上偏移地址量60.
不过这次我们要换个思路,把&num[5]和num转换成char*,再计算差值是:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
#include <stdio.h> int main(int argc, char **argv) { int num[2][3] = { 1, 2, 3, 4, 5, 6 }; int (*p)[3] = num; char *t1 = (char*)&num[5]; char *t2 = (char*)num; printf("diff = %d\n", t1-t2); int *t3 = (int*)&num[5]; int *t4 = (int*)num; printf("diff2 = %d\n", t3-t4); printf("diff3 = %d\n", &num[5]-num); return 0; } |
运行结果分别是
|
1 2 3 4 5 |
diff = 60 diff2 = 15 diff3 = 5 |
我们可以看到diff已经验证了我们的结论了,不过有两个不解的地方,为什么diff2,diff3一个是15,一个是5呢?
其实这是因为指针相减的时候,并不是直接计算处实际的地址差值,而是计算出它们相差了几个指向的元素数据类型,在t1,t2中,我们将指针强转成char*,一个char是一个字节,所以最后算出的就是实际地址差值。
而t3,t4是对应的int*,一个int型相差4个字节,所以算出的差值是&num[5]和num相差了15个int型数据,对应也是60个字节。
最后直接&num[5]-num,被减数和减数都是作为二维数组的行,即对应3个int型元素的一维数组,相差了5个int[3],实际相差地址也就是5*sizeof(int[3])=60字节了。
先说到这,拜~